
Extracting words from text is easy. Extracting the right vocabulary is not. A computer can split a paragraph into tokens and count how often each one appears. The result may include names, dates, headings, common function words, broken fragments, and rare terms that have little value outside the passage.
For language learning, the task is different. To extract vocabulary from text well, you need to rank language by learning value, preserve phrases, and keep enough context to understand the result later.
What Does Vocabulary Extraction Actually Do?
A basic extraction process may separate the text into words, normalize capitalization and word forms, remove very common function words, count frequency, and return the remaining terms.
This is useful for text analysis, but it does not know the learner. A frequent word may already be obvious. A phrase that appears only once may be the most reusable expression in the article. A learning-oriented extractor needs another layer: level, context, phrase detection, relevance, and prior knowledge.
Clean the Source Before Extracting
Remove navigation menus, cookie notices, references, repeated headers, and unrelated captions. Correct obvious OCR errors and broken line endings. If the text contains several unrelated sections, process the relevant section first.
Dirty input produces convincing-looking noise. A menu item repeated ten times can outrank an important phrase simply because it appears in every copied page section.
Define Who the List Is For
The same paragraph should not produce the same list for every learner. A beginner may need common verbs that an advanced reader already knows. An engineer may ignore basic technical terms while saving phrases used to explain trade-offs. A teacher may choose words because they support the next lesson.
Before extraction, define approximate proficiency level, subject or purpose, whether the goal is comprehension or production, whether technical terminology should be included, and how many items the learner can realistically review.
Frequency Is a Signal, Not a Decision
Repeated language is often important, but frequency has limits. In a short text, a central term may occur only once. In a scraped webpage, an irrelevant label may occur many times. Common words can also form valuable phrases whose meaning is not obvious from the parts.
Frequency is a signal, not a decision. Use it alongside importance to the main idea, usefulness across other texts, difficulty for the learner, phrase completeness, likelihood of future use, and whether the context demonstrates a distinct meaning.
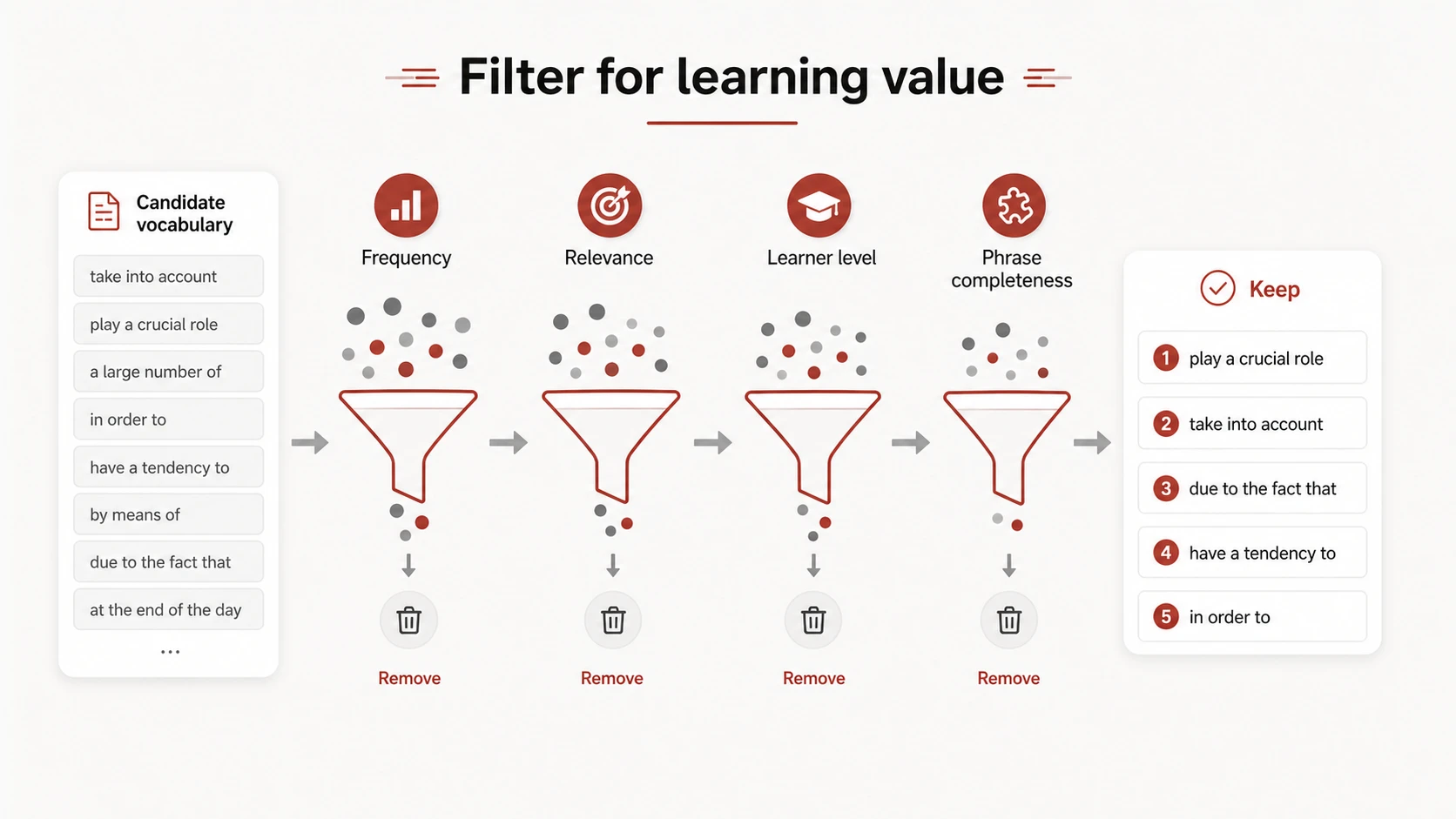
Preserve Multi-Word Expressions
Consider this sentence:
The decline can be attributed to changes in consumer behavior.
An extractor may return decline, attributed, changes, consumer, and behavior. For a learner, be attributed to may be the most valuable item.
Good vocabulary extraction should identify collocations, phrasal verbs, fixed expressions, and recurring sentence frames. These units carry grammar and usage that disappear when the text is split into individual words.
Keep the Meaning Used in This Text
Words such as address, issue, engage, and significant change with context. A list containing every dictionary meaning forces the learner to find the relevant one again.
Keep the source sentence and explain the meaning used there. Add another definition only when it is common and supports the learning goal. Context also prevents false matches. Bear in a wildlife article and bear the cost belong to different learning entries even though the spelling is identical.
Rank Candidates Instead of Accepting Everything
A useful output can place candidates into three groups:
- Learn now: central, reusable, level-appropriate language;
- Understand for this text: necessary but specialized terms;
- Ignore for now: names, obvious words, errors, and low-value items.
This ranking is more honest than pretending every extracted word deserves a flashcard.
Review Automatic Results Manually
Check whether proper names were included, phrases were split incorrectly, the source sentence is complete, the definition matches the passage, the item is already familiar, a common expression was missed, and the final list is small enough to review.
Automatic extraction saves time at the candidate stage. Human review turns candidates into a learning resource.
Use a Context-Aware Text Vocabulary Extractor
A Text to Vocabulary workflow can reduce the repetitive work of copying, checking, and formatting. ClaviSay helps learners bring in real text, identify useful words and phrases, understand them beside the original sentence, and save selected items for later review.
This matters because extraction is not the end goal. The useful outcome is vocabulary you can recognize again, recall without the source, and eventually reuse.
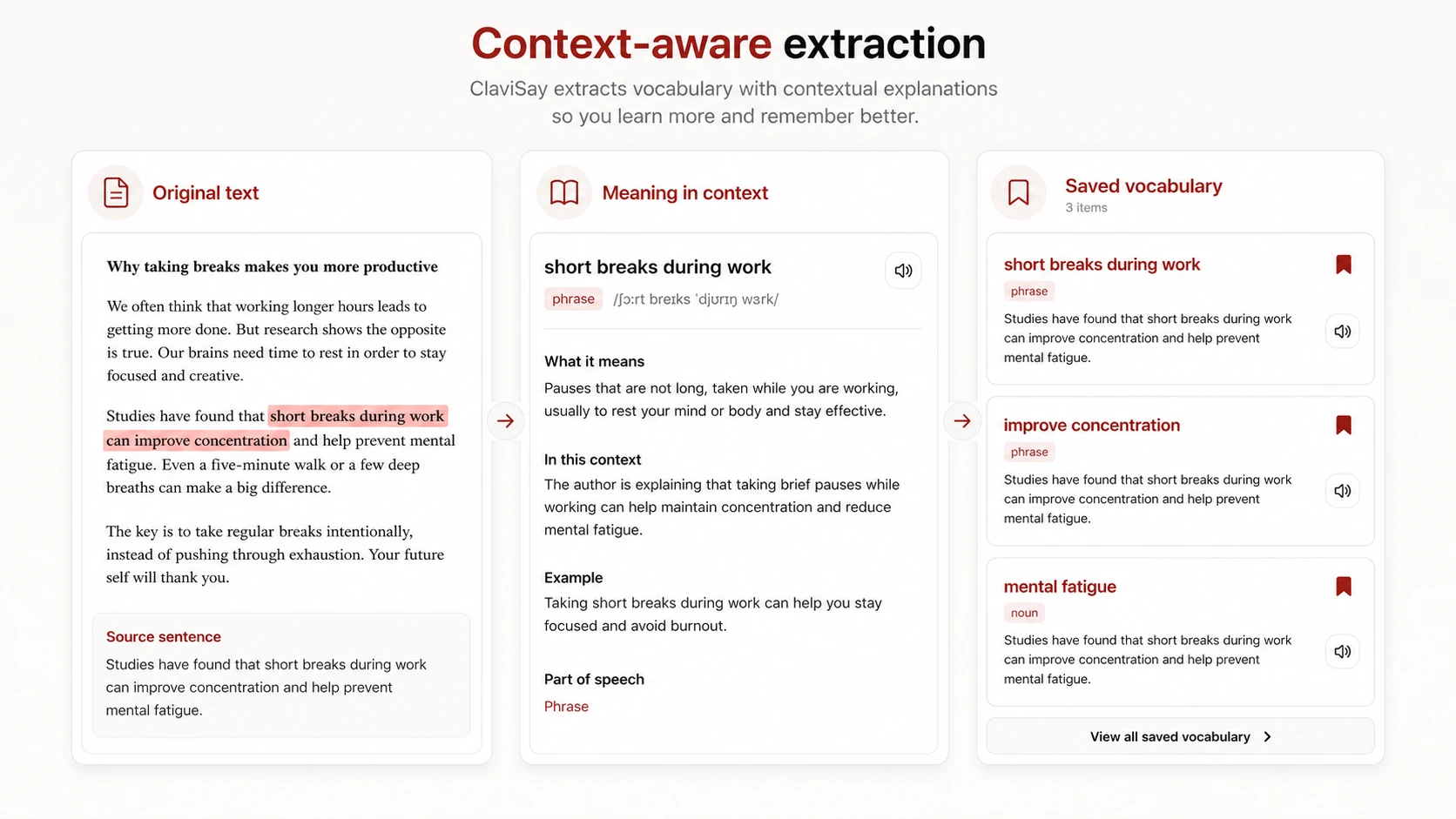
Turn the Extracted List into Practice
Review the list by hiding the target item and completing the source sentence. Then explain the phrase in simpler English or produce a new example.
If you need a formal check, use a Vocabulary Quiz Generator with the cleaned selection. Do not generate questions from raw candidates; irrelevant inputs produce irrelevant tests. Learners building the list manually can follow the companion guide on how to create a vocabulary list from text.
A Short Worked Example
Source:
Although the initial results were promising, the researchers cautioned against drawing firm conclusions from such a limited sample.
Weak extraction might return initial, results, promising, researchers, cautioned, drawing, firm, conclusions, limited, and sample.
Learning-oriented extraction is shorter: promising results, caution against doing something, draw a firm conclusion, and limited sample. The second list captures patterns that make the sentence useful.
Frequently Asked Questions
How do I extract vocabulary from text automatically?
Use a text vocabulary extractor, then review its candidates. Remove noise, restore full phrases, confirm meanings, and keep source sentences.
Is word frequency enough to choose vocabulary?
No. Frequency is one signal. Relevance, difficulty, reusability, phrase structure, and the learner's existing knowledge also matter.
Should an extractor remove common words?
It should remove many common standalone words while still recognizing valuable combinations such as carry out or take into account.
Can I extract vocabulary from long documents?
Yes, but process them section by section. Smaller units make context verification and selection easier.
What is the difference between extracting words and creating a vocabulary list?
Extraction produces candidates. Creating a learning list involves choosing, explaining, organizing, and preparing those candidates for review.
Extraction Is the Beginning, Not the Result
The raw words in a text are not yet a vocabulary lesson. Clean the source, define the learner, preserve phrases, rank by usefulness, and verify the context.
The best extractor is not the one that returns the most words. It is the one that makes a smaller number of good decisions easier. For reading workflows, see how to save vocabulary from articles without breaking focus.